

Created
Aug 10, 2024 10:38 PM
Favorite
Favorite
Priority
备注
推荐
类型
Langchain
Fixing Hallucination with Knowledge Bases
大型语言模型(LLMs)存在数据实时性的问题。即使是像 GPT-4 这样最强大的模型也对最近的事件一无所知。
在 LLMs 看来,世界是静止的。它们只知道通过它们的训练数据所呈现的世界。
这给依赖最新信息或特定数据集的任何用例带来了问题。例如,您可能有一些内部公司文档,您希望通过 LLMs 与之交互。
第一个挑战是将这些文档添加到 LLMs 中,我们可以尝试对这些文档进行训练,但这是耗时且昂贵的。
当添加新文档时会发生什么?对于每个新添加的文档进行训练是非常低效的,简直是不可能的。
那么,我们该如何解决这个问题呢?我们可以使用“检索增强 retrieval augmentation ”的技术。这种技术允许我们从外部知识库中检索相关信息并将该信息提供给我们的 LLMs。
外部知识库是我们窥视 LLMs 训练数据之外世界的“窗口 window ”。在本章中,我们将学习如何使用 LangChain 为 LLMs 实现检索增强。
创建知识库
对于 LLMs,我们有两种主要类型的知识。 “参数化知识 parametric knowledge ”是指 LLMs 在训练过程中学到的一切,它作为 LLMs 对世界的冻结快照。
第二种类型的知识是“源知识 source knowledge”。这种知识涵盖通过输入提示输入 LLMs 的任何信息。当我们谈论“检索增强”时,我们是指给 LLMs 提供有价值的源知识。
(您可以使用 此处的 Jupyter 笔记本 跟随以下章节!)
获取我们的知识库数据 Getting Data for our Knowledge Base
为了帮助我们的 LLMs,我们需要为其提供相关的源知识。为此,我们需要创建我们的知识库。
我们从一个数据集开始。使用的数据集自然取决于用例。
它可以是 LLMs 需要帮助编写代码的代码文档,也可以是内部聊天机器人的公司文档,或者其他任何东西。
在我们的示例中,我们将使用维基百科的一个子集。要获取这些数据,我们将使用 Hugging Face 数据集,如下所示:
In [2]:
Out[2]:
In[3]:
Out[3]:
大多数数据集将包含包含大量文本的记录。
因此,我们的第一个任务通常是构建一个预处理流水线,将这些长文本切割成更简洁的块 Chunks。
创建块 Creating Chunks
将我们的文本分割成较小的块对于多个原因非常重要。主要有以下几点:
- 提高 “ 嵌入 (Embeddings) 准确性 embedding accuracy ” - 这将提高后续结果的相关性。
- 减少输入LLMs的文本量。限制输入可以提高LLMs遵循指示的能力,减少生成成本,并帮助我们获得更快的响应。
- 为用户提供更精确的信息源,因为我们可以将信息源缩小到更小的文本块。
- 对于非常长的文本块,我们将超过嵌入 (Embeddings) 或完成模型的最大上下文窗口。将这些较长的文档拆分使得可以将这些文档添加到我们的知识库中。
为了创建这些块,我们首先需要一种衡量文本长度的方法。LLMs不是按单词或字符来衡量文本的-它们是按“令牌 (Tokens) ”来衡量的。
令牌 (Tokens) 通常是一个词或子词的大小,根据LLMs而异。这些令牌 (Tokens) 本身是使用“标记器 (Tokenizer) ”构建的。
我们将使用
gpt-3.5-turbo作为我们的模型,并且我们可以像下面这样初始化该模型的标记器 (Tokenizer) :使用标记器 (Tokenizer) ,我们可以从纯文本创建标记并计算标记数。我们将将此封装为一个名为
tiktoken_len的函数:In[28]:
Out[28]:
有了我们的标记计数函数,我们可以初始化一个LangChain
RecursiveCharacterTextSplitter对象。该对象将允许我们将文本分割成不超过我们通过chunk_size参数指定的长度的块。现在我们这样分割文本:
In[6]:
Out[6]:
这些块没有超过我们之前设置的400个块大小限制:
In[7]:
Out[7]:
使用
text_splitter,我们可以得到大小合适的文本块。我们将在后面的索引过程中使用此功能。现在,让我们来看看嵌入 (Embeddings) 。创建嵌入 (Embeddings)
向我们的LLMs检索相关上下文非常重要的是矢量嵌入 (Embeddings) 。我们将希望将我们想要存储在知识库中的文本块编码为矢量嵌入 (Embeddings) 。
这些嵌入 (Embeddings) 可以作为每个文本块含义的“数值表示”。这是可能的,因为我们使用另一个AI语言模型将人类可读文本转换为AI可读的嵌入 (Embeddings) 。
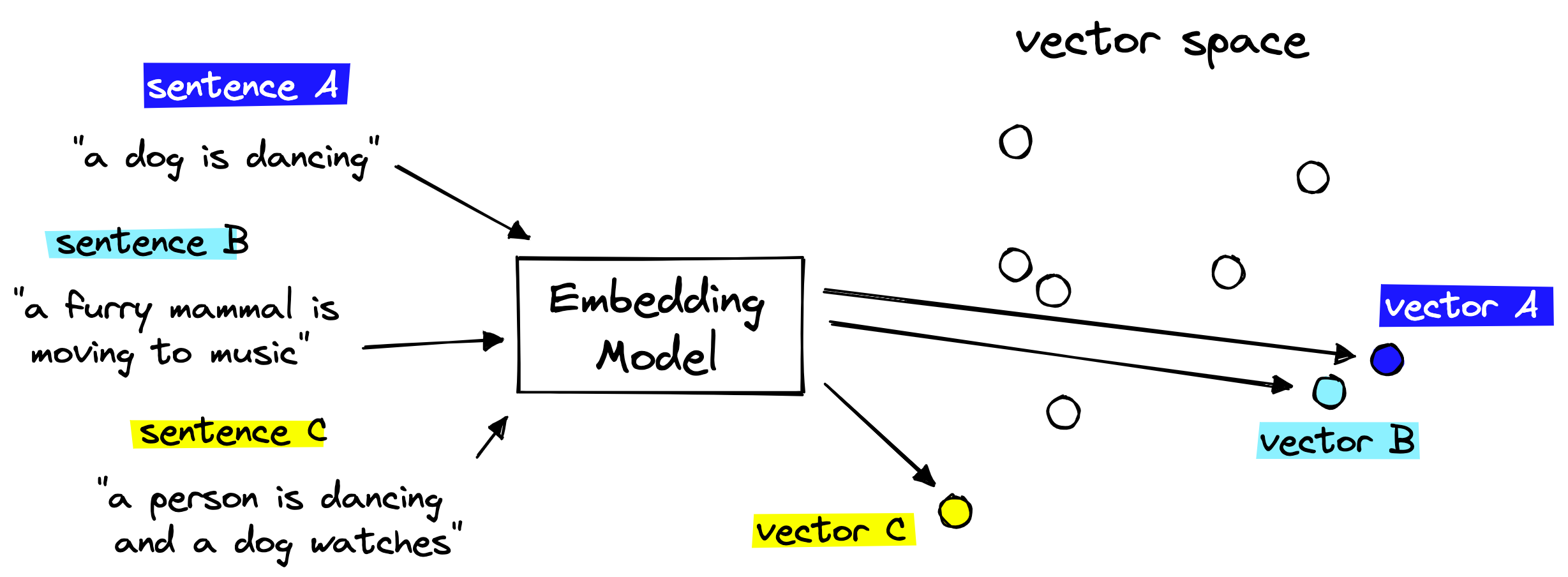
编码器将纯文本转换为嵌入 (Embeddings)
然后,我们将这些嵌入 (Embeddings) 存储在我们的矢量数据库 (Vector Database) 中(稍后详细介绍),并且可以通过计算矢量空间中嵌入 (Embeddings) 之间的距离来找到具有相似含义的文本块。
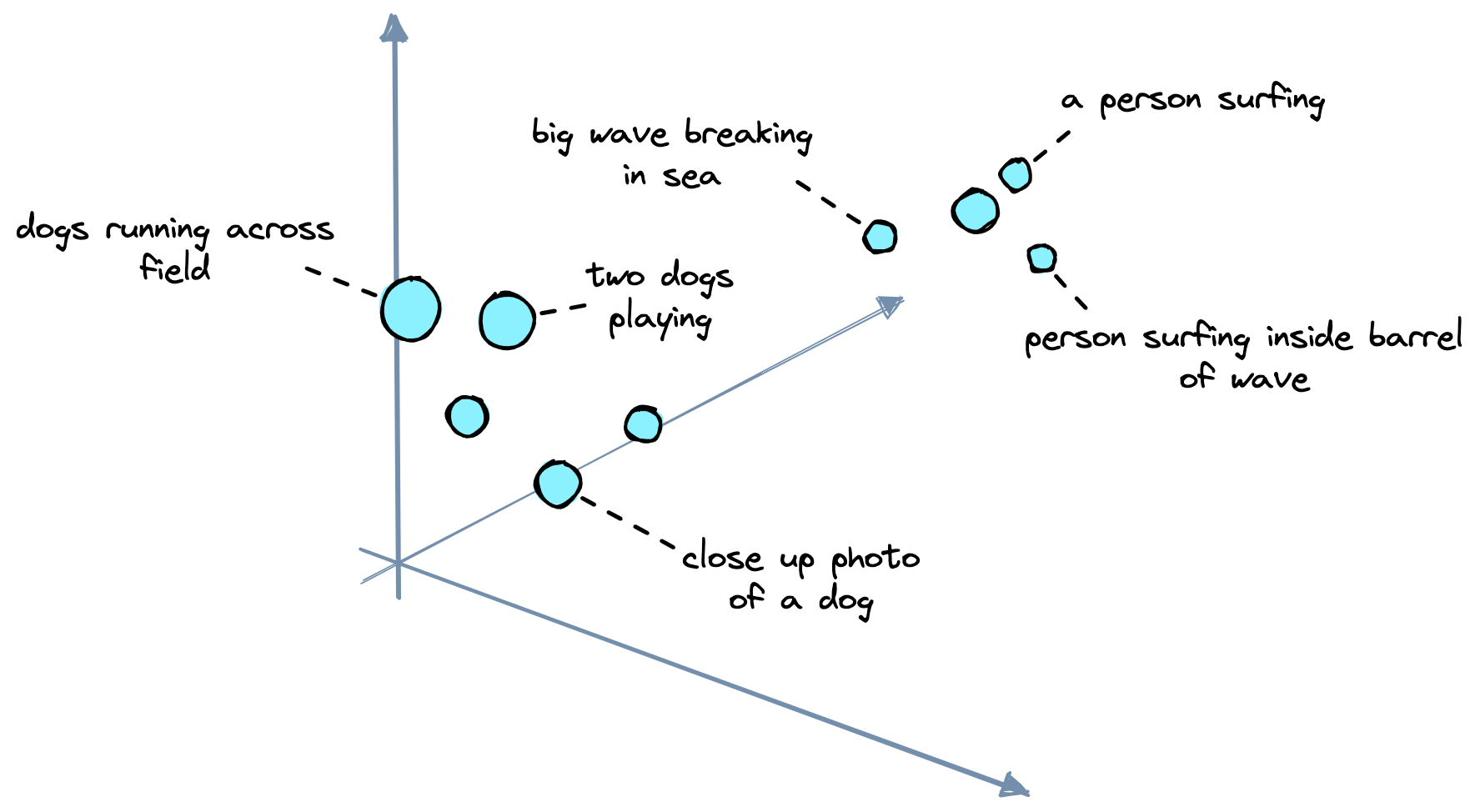
我们将使用的嵌入 (Embeddings) 模型是另一个名为
text-embedding-ada-002的OpenAI模型。我们可以通过LangChain这样初始化它:
现在我们可以嵌入 (Embeddings) 我们的文本:
In[10]:
Out[10]:
从中,我们得到了两个嵌入 (Embeddings) ,因为我们传入了两个文本块。
每个嵌入 (Embeddings) 都是一个1536维的向量。这个维度只是
text-embedding-ada-002的输出维度。有了这些,我们拥有了我们的数据集、文本分割器和嵌入 (Embeddings) 模型。我们拥有了开始构建我们的知识库所需的一切。
矢量数据库 (Vector Database)
矢量数据库 (Vector Database) 是一种知识库类型,允许我们将相似嵌入 (Embeddings) 的搜索扩展到数十亿条记录,通过添加、更新或删除记录来管理我们的知识库,甚至可以执行过滤等操作。
我们将使用Pinecone矢量数据库 (Vector Database) 。要使用它,我们需要一个免费的API密钥。然后我们可以像这样初始化我们的数据库索引:
然后我们连接到新索引:
In[12]:
Out[12]:
我们将看到新的 Pinecone 索引的
total_vector_count为0,因为我们尚未添加任何向量。我们的下一个任务是执行此操作。索引过程包括遍历我们想要添加到知识库中的数据,创建ID、嵌入 (Embeddings) 和元数据,然后将它们添加到索引中。
我们可以批量处理此过程以加快速度。
现在我们已经对所有内容进行了索引。要检查索引中的记录数,我们再次调用
describe_index_stats:In[14]:
Out[14]:
我们的索引包含约27K条记录。如前所述,我们可以将其扩展到数十亿条,但对于我们的示例来说,27K已经足够。
LangChain矢量存储与查询
我们独立构建我们的索引,与LangChain无关。因为这是一个直接的过程,并且使用Pinecone客户端直接完成速度更快。
但是,我们要回到LangChain,所以我们应该通过LangChain库重新连接到我们的索引。
我们可以使用
similarity search方法直接进行查询,并返回文本块,而无需LLM生成响应。In[16]:
Out[16]:
所有这些都是相关的结果,告诉我们我们的系统的检索组件正在发挥作用。
下一步是添加我们的LLM,利用这些检索到的上下文信息来生成答案。
生成式问答
在生成式问答(GQA)中,我们将问题传递给LLM,但指示它基于从知识库返回的信息来回答问题。我们可以在LangChain中轻松实现这一点,使用
RetrievalQA链。让我们尝试使用我们之前的查询:
In[22]:
Out[22]:
这次我们得到的响应是由我们的
gpt-3.5-turbo LLM根据从我们的向量数据库检索到的信息生成的。我们仍然无法完全防止模型产生令人信服但错误的幻觉,这种情况可能发生,并且我们不太可能完全消除这个问题。然而,我们可以采取更多措施来提高对所提供答案的信任。
这样做的一种有效方法是在响应中添加引用,允许用户看到信息的来源。
我们可以使用
RetrievalQAWithSourcesChain的稍微不同版本来实现这一点。In[23]:
In[24]:
Out[24]:
现在我们已经回答了提出的问题,同时还包括了LLM使用的信息的来源。
我们已经学会了如何通过使用矢量数据库 (Vector Database) 作为知识库来为大型语言模型(LLMs)提供源知识的支撑。
通过这样做,我们可以鼓励LLM在回答中保持准确性,保持源知识的最新状态,并通过为每个答案提供引用来提高对我们系统的信任。
我们已经看到LLMs和知识库在诸如Bing的AI搜索、Google Bard和ChatGPT插件等大型产品中配对使用。
毫无疑问,LLMs的未来与高性能、可扩展和可靠的知识库密切相关。
![2024_年终总结: [代码与咖啡]打工人的漂流记](https://www.notion.so/image/https%3A%2F%2Fprod-files-secure.s3.us-west-2.amazonaws.com%2F68202bb5-9faf-4bfe-9cc4-aaf29bc1fbcc%2Fb7607bba-e20c-4a48-83e7-cdbac70ebdbf%2Fcodecoffee.jpg?table=block&id=e0566808-4d66-401f-b9c8-6d4fd5f8a9a4&t=e0566808-4d66-401f-b9c8-6d4fd5f8a9a4&width=800&cache=v2)

