
Created
Jun 17, 2024 09:11 AM
Favorite
Favorite
Priority
备注
推荐
🌟🌟🌟🌟
类型
模型部署
阅读量2k 收藏 31
点赞数 66
版权
6 篇文章 6 订阅
订阅专栏
博客导读:
《AI—工程篇》
《AI—模型篇》
目录
一.引言
上一篇大语言模型推理服务框架—Ollama介绍了Ollama,Ollama以出色的设计一行命令完成推理框架部署,一行命令完成大模型部署,模型的下载不依赖梯子,速度非常快,大幅提升模型部署效率,同时,当有多卡GPU时,Ollama可以自动将模型分片到各个GPU上,博主使用V100显卡(单卡32G显存)部署llama3 70B(预计需要40G显存),自动完成了显存分配。
今天来介绍一下Xinference,与Ollama比较,Xinference自带Webui与用户交互更加友好,只需点一下所需要的模型,自动完成部署,同时,Xinference在启动时可以指定Modelscope社区下载模型,对于无法登陆抱抱脸的伙伴,可以大幅提升模型下载效率。
这里还是想说两句,大模型领域,美帝目前确实是领先的,我们能做的只能是努力追赶,但在追赶的过程中发现,好多优秀的大模型领域开源项目,都是默认配置hugging face的,一方面是下载模型时间甚至超过了熟悉项目本身,另一方面是压根连不上导致项目跑不起来,导致在这片土地上水土不服。当然对在这片热土上生存的企业及工程师,可能学习门槛的提升,也是一件好事,天热的技术护城河哈哈
二.一行代码完成Xinference本地部署
- docker run -it:启动docker容器并在内部使用终端交互
- -name xinference:指定docker容器名字为xinference,如不设置随机生成
- d:后台运行,如果不设置会进入到docker容器内
- p:9997:9997,宿主机端口:docker容器端口
- e XINFERENCE_MODEL_SRC=modelscope:指定模型源为modelscope,默认为hf
- e XINFERENCE_HOME=/workspace:指定docker容器内部xinference的根目录
- v /yourworkspace/Xinference:/workspace:指定本地目录与docker容器内xinference根目录进行映射
- -gpus all:开放宿主机全部GPU给container使用
- xprobe/xinference:latest:拉取dockerhub内xprobe发行商xinference项目的最新版本
- xinference-local -H 0.0.0.0:container部署完成后执行该命令
三.两行代码完成Xinference分布式部署
master部署:
work部署:
四.开箱即用webui
1.Launch Model
启动模型,包含语言模型、图片模型、语音模型、自定义模型,提供了模型搜索框,基本主流模型都已经收录。
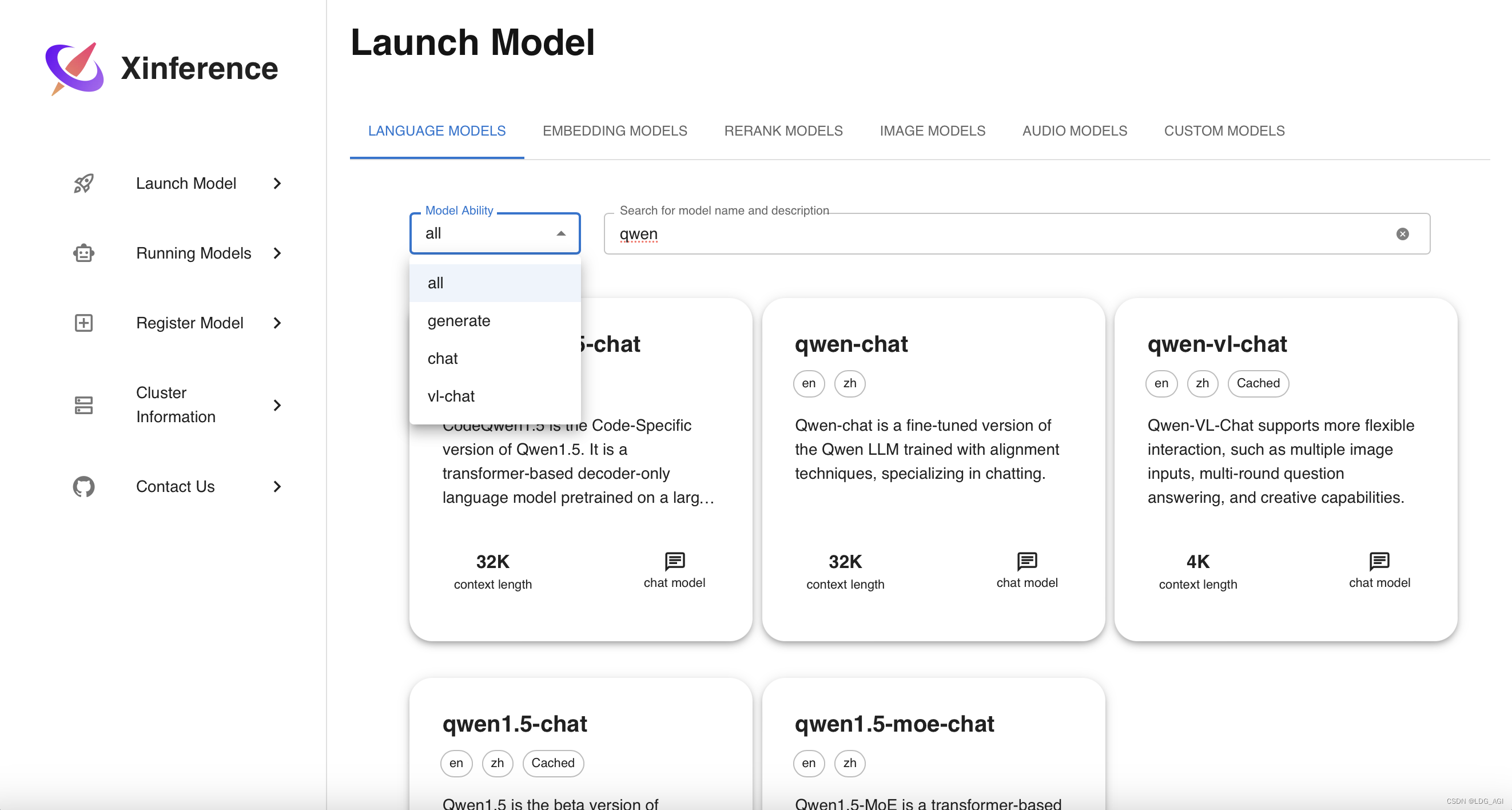
以qwen1.5为例,搜索qwen1.5选择chat版本:
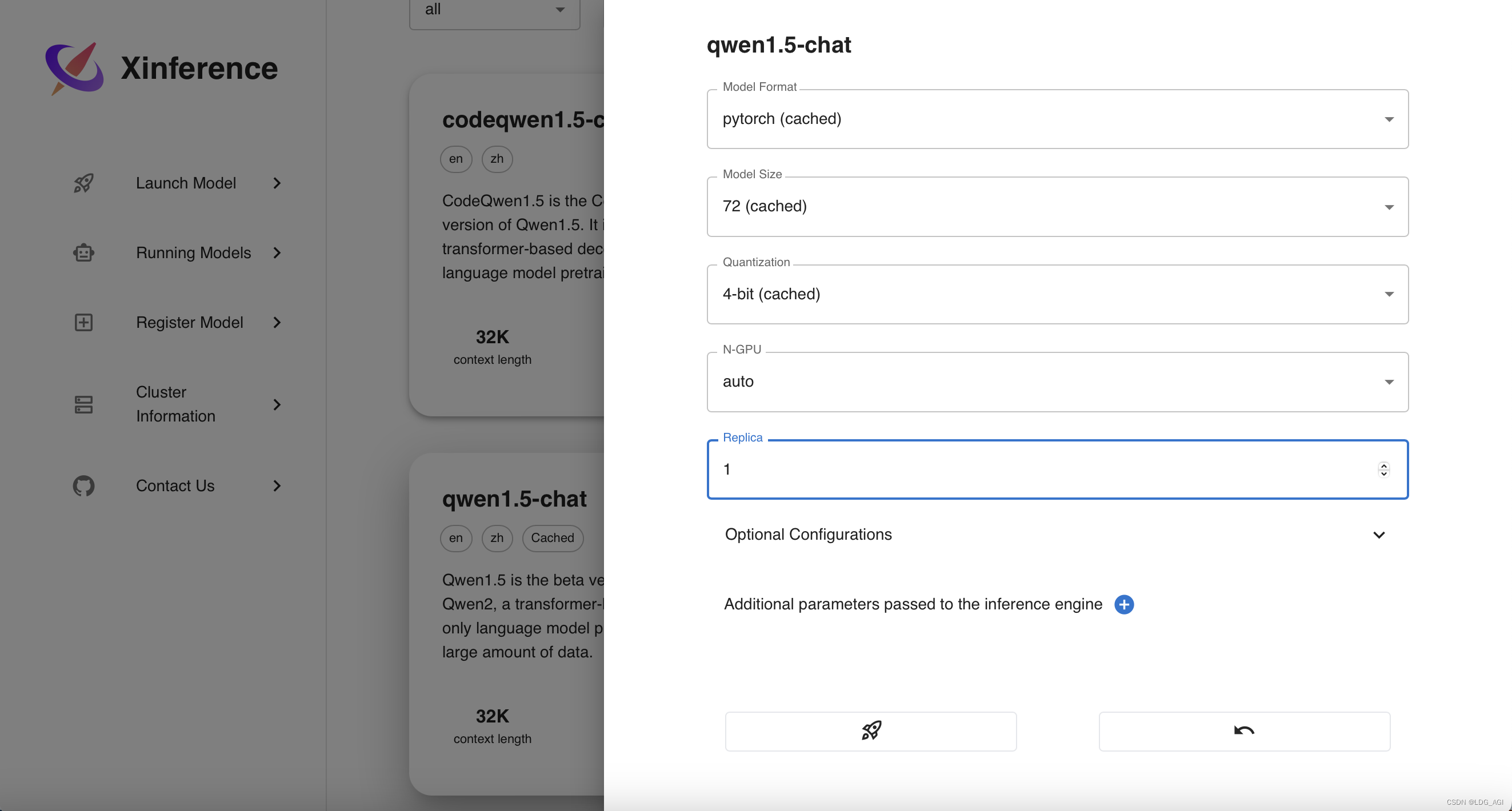
Model Format(模型格式):包含pytorch、gptq、awq、ggufv2等
- Model Size(模型尺寸):包含0.5B~110B全尺寸模型,
- Quantization(模型量化):包含4位、8位、不量化等
- N-GPU(使用GPU数):可以自动或手动选择使用GPU数
- Replica(副本数量):提供服务的副本数量
点击下面的小火箭,发射(启动)模型模型,会去modelscope上自动下载模型并启动
2.Running Models
模型下载启动后,在Running Models内可查看,可以点击Actions下面的窗口弹出测试UI
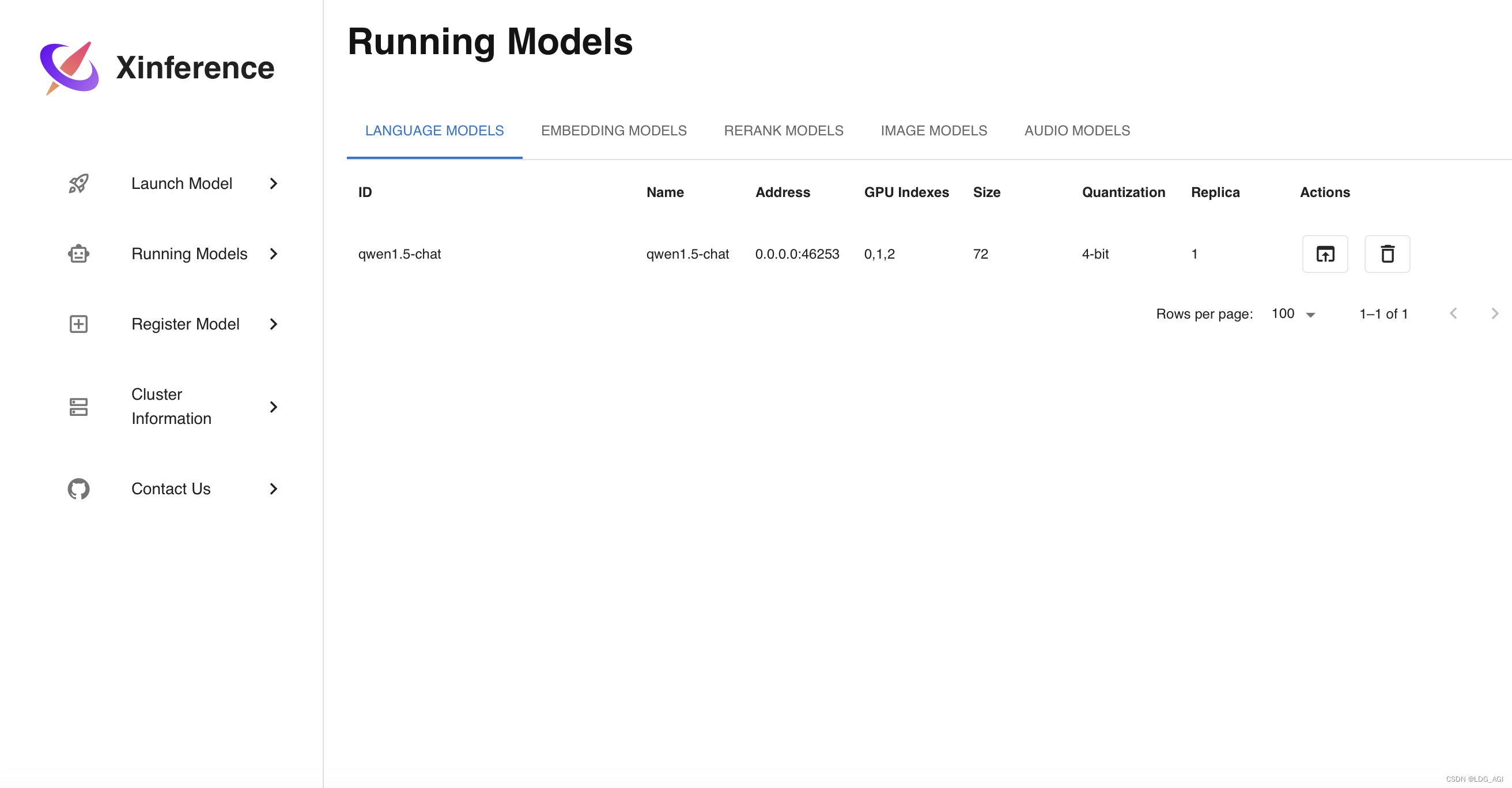
- ID:模型id,后面在调用的时候会用到
- Name:模型name,后面在调用的时候会用到
- Address:模型部署的container端口,后面只会用到宿主机的地址和端口,container状态下后面不需要
- GPU Indexes:GPU索引,Xinference框架会自动根据GPU资源情况切分模型部署在多张卡上
- Size,Quantization:模型尺寸与量化位数
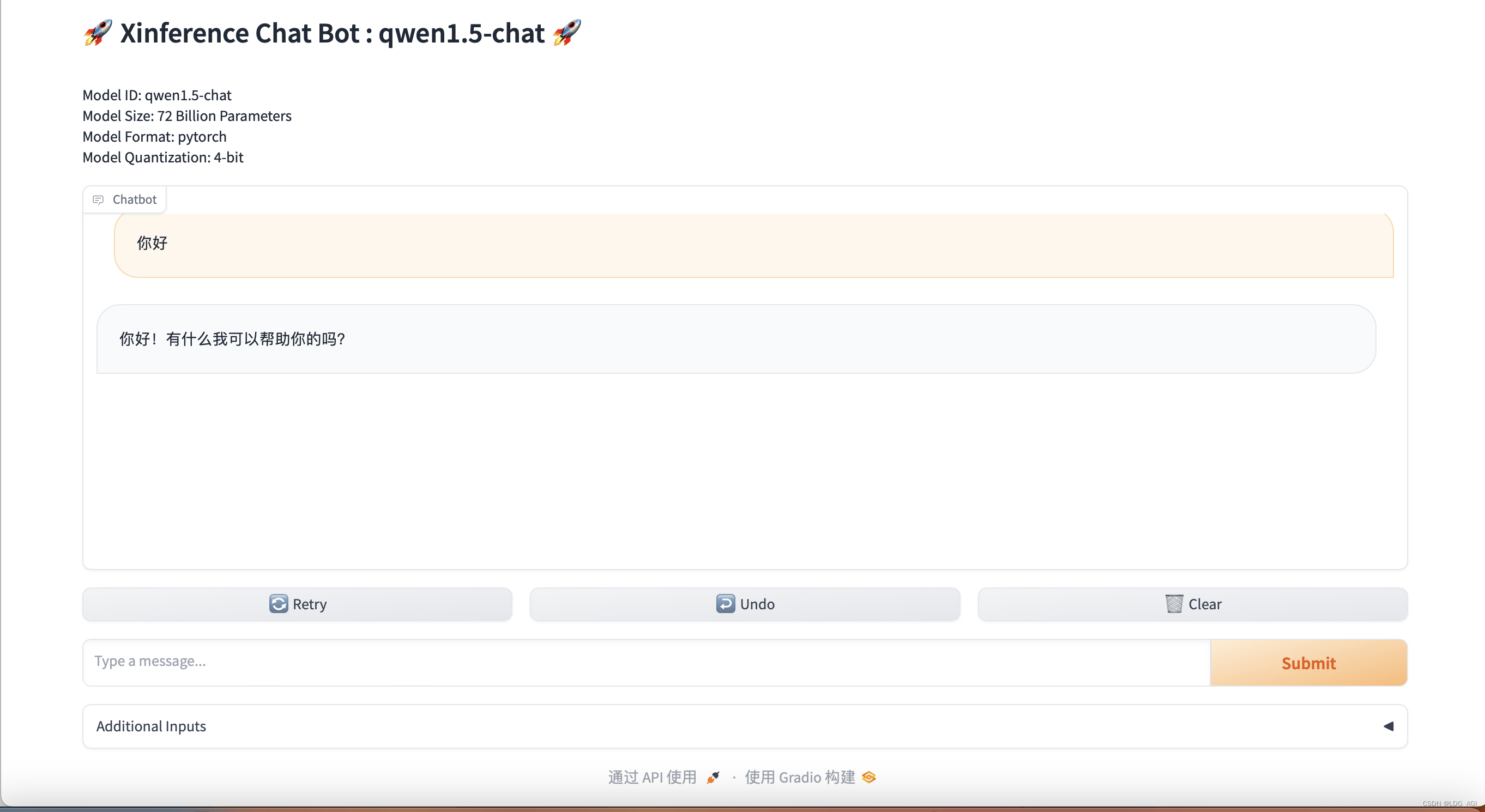
2.1测试qwen1.5-chat
2.2模型存储路径
在启动docker container时,指定了container根目录并且指定了宿主机关联路径:
- e XINFERENCE_HOME=/workspace
- v /yourworkspace/Xinference:/workspace
这样不用登陆container在宿主机本地也可以查看下载到的模型
3.Register Model
你也可以注册自己下载或微调后的模型:
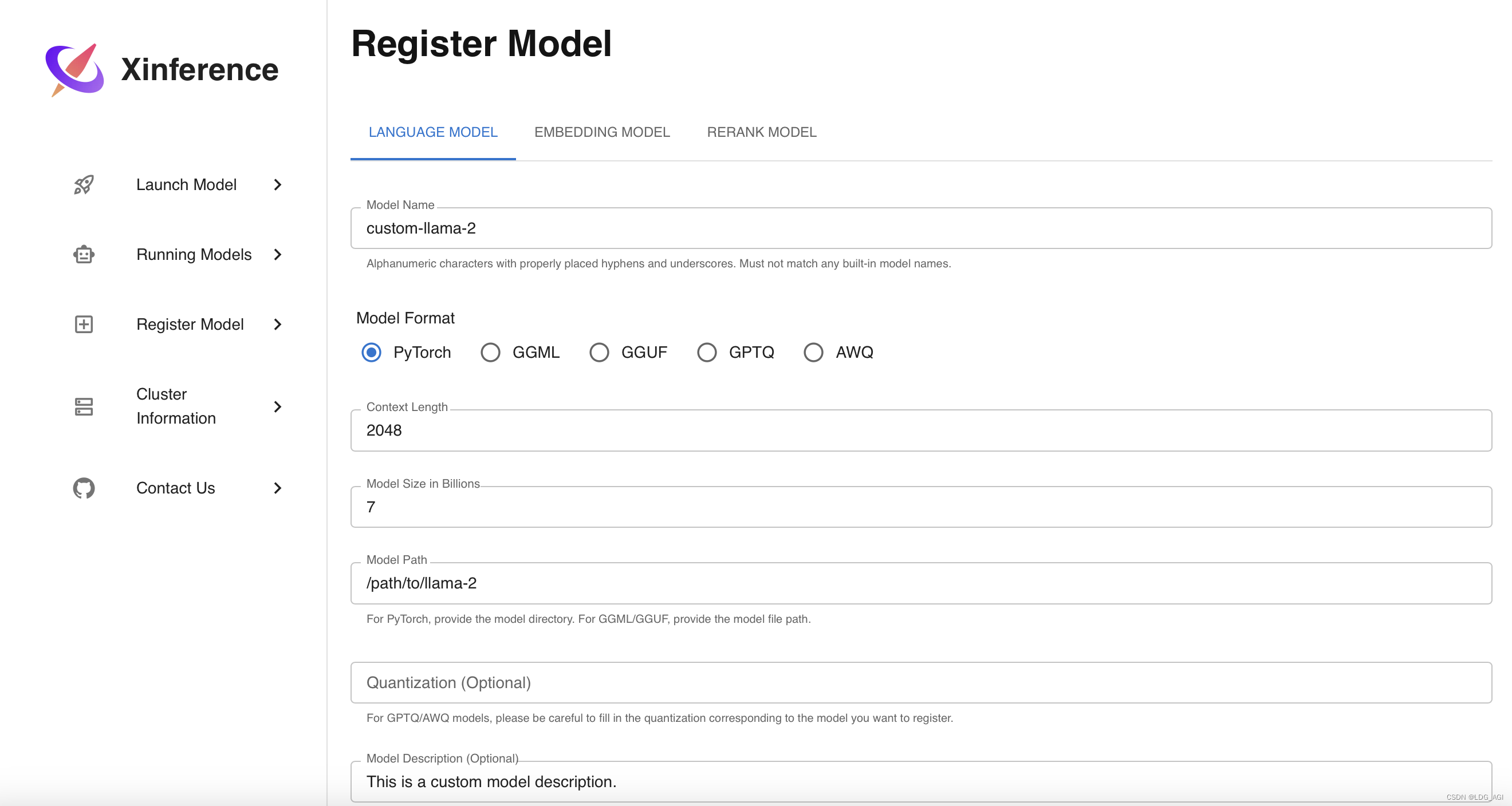
只需要配置模型名、模型格式、上下文长度、模型尺寸、模型路径等
注册完成后在Launch Model — Custom Models 内启动即可。
4.Cluster Information
这里会展示集群Supervisor节点和worker节点的数量以及具体CPU、GPU使用情况,方便管理。
五.模型使用
参考上一篇Ollama,我们可以使用curl或者dify平台调用Xinference部署的推理服务,
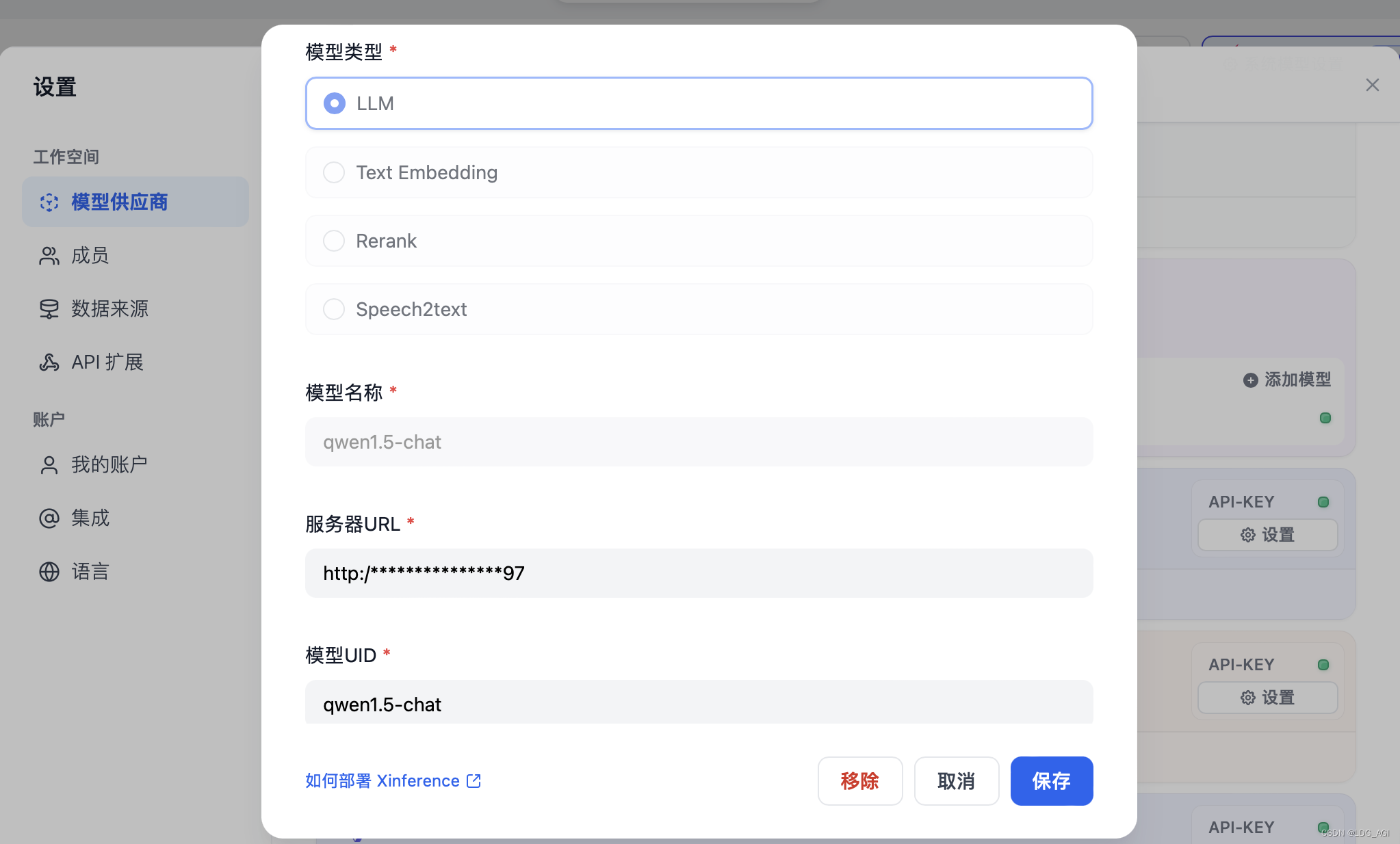
DIFY:只需要配置模型名称、服务器URL、模型UID,其中模型名称和模型UID在Running Models列表中可以查到,服务器URL是http://宿主机host:port。记得带http://否则会报错。
CURL:
与OpenAI一样的post请求:
返回:
OpenAI兼容的API:
Xinference 提供了与 OpenAI 兼容的 API,所以可以将 Xinference 运行的模型直接对 OpenAI模型进行替代
六.总结
本文简要讲述了一行代码完成Xinference本地部署以及两行代码完成Xinference分布式部署以及webui和接口调用,其中快捷部署、极为友好的webui、可配modelscope以及提供兼容OpenAI的API等诸多优点,实属良心之作。
真诚的希望通过写博客的方式将自己涉猎过的大模型开源项目分享给大家,由于个人经历有限,不能保证每篇文章都写的特别深入,但尽量保证内容自己实际操作过,避免大家重复踩坑。如果想了解更多关于Xinference大模型推理框架的内容,可参考官方文档:Xinference官方文档 。
最后,还是很期待大家关注、点赞、评论、收藏噢,您的鼓励是我持续码字的动力!
如果您对AI感兴趣,可以接着看看我的其他文章:
《AI—工程篇》
《AI—模型篇》
关注博主即可阅读全文
- 66
专栏目录
03-22
人工智能学习总结成果,希望可以帮到大家,有疑问欢迎随时沟通~ 人工智能学习总结成果,希望可以帮到大家,有疑问欢迎随时沟通~ 人工智能学习总结成果,希望可以帮到大家,有疑问欢迎随时沟通~ 人工智能学习总结成果,希望可以帮到大家,有疑问欢迎随时沟通~ 人工智能学习总结成果,希望可以帮到大家,有疑问欢迎随时沟通~
02-24
本节内容预备资料:1.FFmpeg:链接:https://pan.baidu.com/s/1jonSAa_TG2XuaJEy3iTmHg密码:w6hk2.baidu-aip:pipinstallbaidu-aip终于进入主题了,此篇是人工智能应用的重点,只用现成的技术不做底层算法,也是让初级程序员快速进入人工智能行业的捷径目前市面上主流的AI技术提供公司有很多,比如百度,阿里,腾讯,主做语音的科大讯飞,做只能问答的图灵机器人等等这些公司投入了很大一部分财力物力人力将底层封装,提供应用接口给我们,尤其是百度,完全免费的接口既然百度这么仗义,咱们就不要浪费掉怎么好的资源,从百度AI入手,开启人工智
1944
本文首先结合自己的工作写了一些对Agent AI智能体的见解,接着介绍了Dify框架快捷部署的过程,最后阐述了Dify框架的特点。个人认为Dify的发展会让Agent AI智能体开发提效,涌现更多有趣有价值的AI应用。
4174
Xorbits Inference(Xinference)是一个性能强大且功能全面的分布式推理框架。可用于各种模型的推理。通过 Xinference,你可以轻松地一键部署你自己的模型或内置的前沿开源模型。无论你是研究者,开发者,或是数据科学家,都可以通过 Xinference 与最前沿的 AI 模型,发掘更多可能。
1188
项目地址: Xorbitsai/inference正如同Xorbits Inference(Xinference)官网介绍是一个性能强大且功能全面的分布式推理框架。可用于大语言模型(LLM),语音识别模型,多模态模型等各种模型的推理。通过 Xorbits Inference,你可以轻松地一键部署你自己的模型或内置的前沿开源模型。无论你是研究者,开发者,或是数据科学家,都可以通过 Xorbits Inference 与最前沿的 AI 模型,发掘更多可能。介绍这个项目主要是为了后面在dify能够快速部署接入AP
1878
Xorbits Inference(Xinference)是一个性能强大且功能全面的分布式推理框架。可用于大语言模型(LLM),语音识别模型,多模态模型等各种模型的推理。通过 Xorbits Inference,你可以轻松地一键部署你自己的模型或内置的前沿开源模型。无论你是研究者,开发者,或是数据科学家,都可以通过 Xorbits Inference 与最前沿的 AI 模型,发掘更多可能。
01-18
大模型时代的智能运维(AIOps)是指利用人工智能技术来提升运维效率和质量的方法。随着企业业务的快速发展和数字化转型的加速,传统的运维方式已经无法满足需求,而AIOps可以通过对大量数据的分析和处理,自动识别和...
09-20
Xinference 也允许从其他模型托管平台下载模型。无论你是研究者,开发者,或是数据科学家,都可以通过 Xorbits Inference 与最前沿的 AI 模型,发掘更多可能。通过 Xorbits Inference,你可以轻松地一键部署你自己的模型或内置的前沿开源模型。如果你的第1个cuda 被占用,又设置 N-GPU 为 auto,可能会报如下错误。可用于大语言模型(LLM),语音识别模型,多模态模型等各种模型的推理。模型缓存地址,我使用 modelscope 下载模型,被缓存到。
4357
9709
本课程来自深度之眼《大模型——前沿论文带读训练营》公开课,部分截图来自课程视频。向量空间中词表示的有效估计Hugo Touvron等Meta AI2023 arxivChatGPT相关工具:https://github.com/pengwei-iie/A_survey_and_tools_of_ChatGPT不过貌似好多都很麻烦,要部署,直接能用的没看见。。。「什么是LLaMA:」
1906
确实可以运行音频大模型。可以将音频文件转换成文本。可以做啥呢?可以直接录用转文字,或者做字幕。transcriptions 是音频转文本translations 可以直接将音频翻译成英文。使用large 模型就可以翻译:本列表列出香港航空的航点 > 翻译成:还集成了翻译模块。
04-29
大语言模型和自然语言模型都是指用机器学习的方法来处理自然语言的模型。其中,大语言模型通常指的是参数数量非常大的模型,例如OpenAI的GPT-3模型就有175亿个参数。而自然语言模型则是一个更加通用的术语,包括了各种不同规模和结构的自然语言处理模型。 虽然大语言模型和自然语言模型的范围存在一定的区别,但它们之间也有一些共同点。比如,它们都需要通过大量的自然语言数据来进行训练,以提高其在自然语言处理任务上的表现。 此外,大语言模型与自然语言模型之间最大的区别在于它们所处理的数据量和难度。大语言模型需要处理海量的文本数据,并且需要具有非常强大的推理和生成能力,以便在各种不同的自然语言处理任务中取得好的表现。而自然语言模型则可以是更加轻量级的模型,主要应用于一些较为简单的自然语言处理任务,如情感分析、文本分类等。
“相关推荐”对你有帮助么?
- 非常没帮助
- 没帮助
- 一般
- 有帮助
- 非常有帮助
- 400-660-0108
- 工作时间 8:30-22:00
- ©1999-2024北京创新乐知网络技术有限公司
LDG_AGI 码龄4年 企业员工 39 原创 20 周排名 1万+ 总排名 6万+ 访问 等级 3914 积分 5049 粉丝 1963 获赞 1656 评论 1712 收藏 私信 关注
热门文章
• 【机器学习】Qwen2大模型原理、训练及推理部署实战 5992
• 【机器学习】GLM4-9B-Chat大模型/GLM-4V-9B多模态大模型概述、原理及推理实战 4935
• 【机器学习】基于YOLOv10实现你的第一个视觉AI大模型 4577
• 【机器学习】Qwen1.5-14B-Chat大模型训练与推理实战 4316
• 【机器学习】QLoRA:基于PEFT亲手微调你的第一个AI大模型 3543
分类专栏
• Python 11篇
• AI智能体研发之路-工程篇 6篇
• Transformers 7篇
• AI智能体研发之路-模型篇 9篇
• PyTorch 2篇
最新评论
• 【python】python指南(十二):Json与dict、list互相转换
MUKAMO: 这篇博文为Python开发者提供了一份关于如何在Python中实现JSON与字典、列表之间互相转换的详细指南。通过掌握这些转换技巧,开发者可以更方便地处理JSON数据,并在Python应用程序中有效地使用它。
• 【机器学习】基于YOLOv10实现你的第一个视觉AI大模型
天才大狗b: 这不就是普通不过的yolo,v几都能实现,这和大模型有什么关系
• 【python】python指南(十二):Json与dict、list互相转换
LeoToJavaer: 博主的文章细节很到位,兼顾实用性和可操作性,内容和细节都很到位,期待博主持续带来更多好文
• 【python】python指南(十二):Json与dict、list互相转换
猫头虎: 🐅🐾🚀 结构清晰,内容丰富,条理分明!这篇博客非常值得一读。猫头虎在线等待更新!📡
• 【python】python指南(十二):Json与dict、list互相转换
✿༺小陈在拼命༻✿: 干货啊,这篇博客深入探讨了机器学习的多面世界,涵盖了从理论到应用和未来的展望。内容详实,讲解清晰,对于机器学习的新手来说非常有帮助。作者不仅介绍了机器学习的基础理论,还分享了一些实际应用案例和未来趋势的预测,让人受益匪浅。感谢作者的分享!
大家在看
• 网络安全系统教程+渗透测试+学习路线(自学笔记)
• Codesys 编程实现随机数字+仿照rand()原理+代码下载 336
• Python之eval函数的使用 1
• python中进程的几种创建方式
• SSH配置、跨主机上传下载、Wrapper访问控制实验操作步骤
最新文章
• 【python】python指南(十二):Json与dict、list互相转换
• 【python】python指南(十一):静态类型注解之Optional
• 【python】python指南(十):静态类型注解之Union 2024年39篇
目录
1. 一.引言
2. 二.一行代码完成Xinference本地部署
3. 三.两行代码完成Xinference分布式部署
4. 四.开箱即用webui
5. 五.模型使用
6. 六.总结
