
Created
Jun 20, 2024 07:12 AM
Favorite
Favorite
Priority
备注
推荐
🌟🌟🌟🌟🌟
类型
模型微调
什么是Axolotl?
Axolotl[1] 是一个旨在简化各种AI模型的微调过程的工具,支持多种配置和架构。
特点:
- 训练各种Huggingface模型,例如llama、pythia、falcon、mpt•支持fullfinetune、lora、qlora、relora和gptq•使用简单的yaml文件或CLI覆盖自定义配置•加载不同的数据集格式,使用自定义格式或者自带的分词数据集•集成了xformer、flash attention、rope scaling和multipacking•支持单个GPU或多个GPU,通过FSDP或Deepspeed进行加速•可以轻松在本地或云端使用Docker运行•将结果和可选的检查点记录到wandb•还有更多功能!
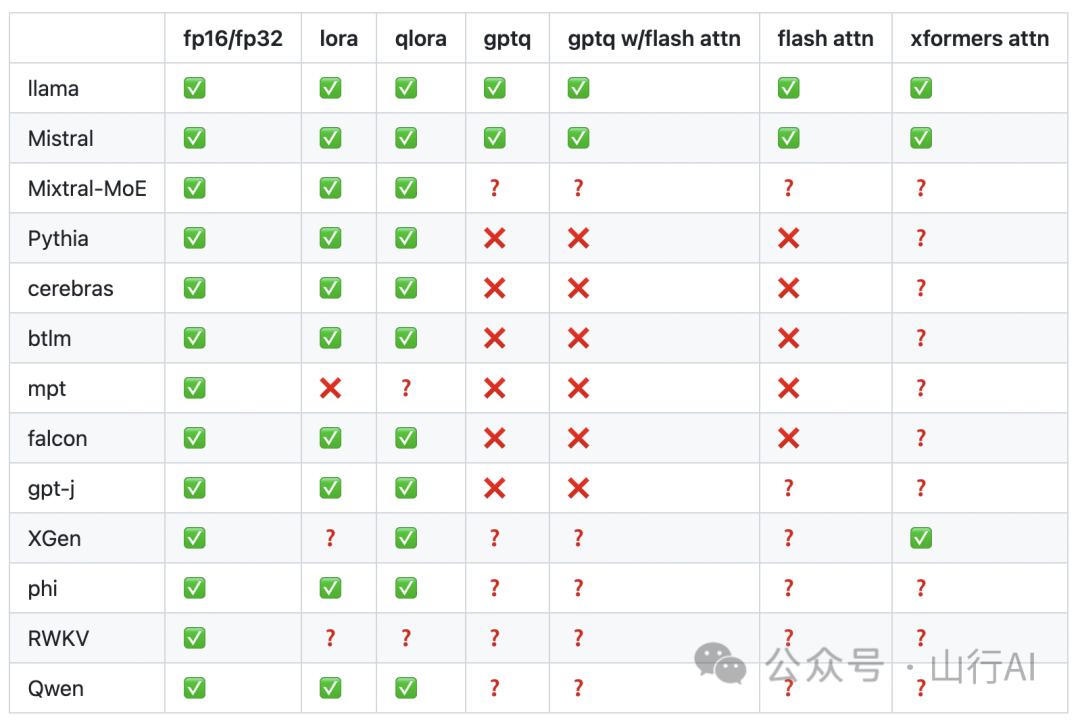
支持的模型
什么是fine-tuning?
预训练模型主要获得的是一般的语言知识,而缺乏对特定任务或领域的具体知识。为了弥补这一差距,接下来进行微调的步骤。
微调使我们能够专注于预训练模型的能力,并优化其在下游特定任务上的性能。 Fine-tuning 意味着对一个预训练模型进行进一步训练,使用新的任务和新的数据。通常,这意味着对整个预训练模型进行训练,包括其所有的部分和设置。但是这可能需要大量的计算资源和时间,特别是对于大型模型来说。 参数高效微调(Parameter-efficient fine-tuning),另一方面,是一种仅关注预训练模型部分设置的微调方式。在训练过程中,它会找出对于新任务最重要的参数,并仅对其进行修改。这使得参数高效微调更快,因为它不需要处理模型的所有参数。
实施堆栈
- Runpod:RunPod[2] 是一个云计算平台,主要用于人工智能和机器学习应用,提供GPU实例、无服务器GPU和AI终端。我们使用了1个NVIDIA 80GB GPU。•Axolotl:用于简化各种人工智能模型微调的工具。•Dataset:teknium/GPT4-LLM-Cleaned[3]•LLM:openlm-research/open_llama_3b_v2 模型[4]
微调实现
安装所需依赖
切换到axolotl文件夹
安装完依赖项后,请查看示例文件夹。其中包含几个带有相应lora配置文件的LLM模型。在这里,我们使用openllama 3b作为基础LLM。我们将查看它的配置文件 ./axolot/examples[5]/openllama-3b[6]/lora.yml。lora.yaml文件包含了微调基础模型所需的配置。
什么是LoRA?
- 它是一种旨在加速LLM(Language Learning Model)训练过程的训练方法。•它通过引入一对秩分解权重矩阵来帮助减少内存消耗。它将LLM的权重矩阵分解为低秩矩阵。这减少了需要训练的参数数量,同时仍保持原始模型的性能。•这些权重矩阵被添加到已存在的权重矩阵(预训练的)中。
与LoRA相关的重要概念
- 预训练权重的保留:LoRA保留了冻结层的先前训练权重。这有助于防止灾难性遗忘现象的发生。LoRA不仅保留了模型的现有知识,还能很好地适应新数据。•训练权重的可移植性:LoRA中使用的排名分解矩阵具有显著较少的参数。这使得训练后的LoRA权重可以在其他环境中被利用和转移。•与注意力层的整合:LoRA权重矩阵基本上被整合到原始模型的注意力层中。这允许对模型调整到新数据的上下文进行控制。•内存效率高,因为它将微调过程的计算减少了3倍。 lora.yaml文件中的配置。我们可以通过在lora.yaml文件中的base_model和datasets参数指定相应的值来设置基础模型和训练数据集。
Lora超参数
lora_r: 它决定了在权重矩阵上应用多少个等级分解矩阵,以减少内存消耗和计算需求。根据LoRA论文,默认或最小等级值为8。
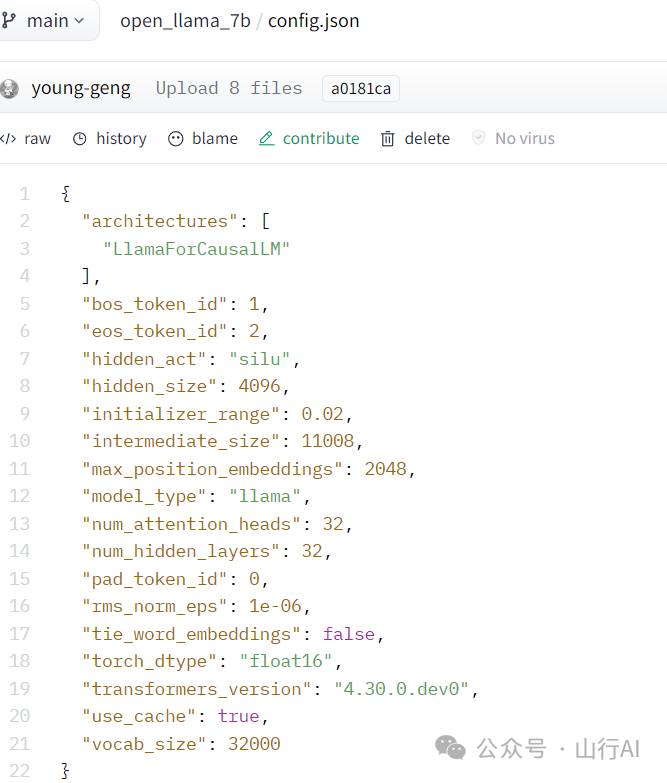
- 更高的等级会导致更好的结果,但需要更高的计算能力。•随着训练数据复杂性的增加,需要更高的等级。•要与完整的微调匹配,权重矩阵的等级应与基础模型的隐藏层数量相匹配。可以从config.json中找到模型的隐藏大小(“num_hidden_layers”:32)。
lora_alpha: LoRA的缩放因子决定了模型在训练过程中调整矩阵更新的贡献程度。
- 较低的alpha值更重视原始数据,并更大程度上保持模型的现有知识,即更倾向于模型的原始知识。
lora_target_modules:它确定要训练的特定权重和矩阵。最基本的是q_proj(查询向量)和v_proj(值向量)。
- Q投影矩阵应用于transformers块中注意机制中的查询向量。它将隐藏状态转换为所需的维度,以实现有效的查询展示。•V投影矩阵将隐藏状态转换为所需的维度,以实现有效的值表示。
Lora Fine-tune
- 训练在Nividia A 100 80 GB GPU上花费了1小时45分钟•训练检查点会保存在lora.yaml文件中指定的lora-out文件夹中,这是输出目录。•适配器文件也会保存在lora.yaml文件中指定的输出目录中。•可以通过在lora.yaml文件中的push_dataset_to_hub参数中指定repoid和文件夹详细信息来将训练好的模型推送到huggingface存储库。
使用gradio进行交互式推理
gradio
结论
在这里,我们探讨了如何利用Axolotl,并使用gradio对经过微调的模型进行几乎没有代码微调和推理。
本文由山行翻译整理自:https://medium.aiplanet.com/no-code-llm-fine-tuning-using-axolotl-2db34e3d0647和[GitHub - OpenAccess-AI-Collective/axolotl: Go ahead and axolotl questions](https://github.com/OpenAccess-AI-Collective/axolotl),核心目的是向大家分享更多AI相关的知识,让更多的人能够对AI有一个清晰的认识。如果对您有帮助,请帮忙点赞、关注、收藏,谢谢~
References
[1] Axolotl: https://github.com/OpenAccess-AI-Collective/axolotl [2] RunPod: https://www.runpod.io/console/gpu-cloud [3] teknium/GPT4-LLM-Cleaned: https://huggingface.co/datasets/teknium/GPT4-LLM-Cleaned [4] openlm-research/open_llama_3b_v2 模型: https://huggingface.co/openlm-research/open_llama_3b_v2 [5] examples: https://github.com/OpenAccess-AI-Collective/axolotl/tree/main/examples [6] openllama-3b: https://github.com/OpenAccess-AI-Collective/axolotl/tree/main/examples/openllama-3b